2. 육각형 아키텍처
비즈니스 로직을 순수하게
저는 육각형 아키텍처(Hexagonal Architecture)를 책 『만들면서 배우는 클린 아키텍처』1 에서 처음 알게 되었습니다. 고전적인 엔터프라이즈 아키텍처인 3 Layered Architecture 보다 훨씬 장점이 많다고 느껴서 실무에도 적극적으로 사용하고 있습니다.
제가 느낀 가장 큰 장점은, GUI(Graphic User Interface)나 http, 데이터베이스같은 외부 의존성을 비즈니스 로직과 철저하게 분리할 수 있다는 것입니다. 비즈니스 로직이 세부사항2에 오염되지 않도록 순수하게 유지하라는 말은 로버트 마틴이 『클린 아키텍처』3에서 언급했던 바이고, 에릭 에반스의 『도메인 주도 설계』4의 내용과도 일맥상통합니다.
육각형 아키텍처는 앨리스테어 코어번(Alistair Cockburn)이 2005년에 정의했습니다. 코어번은 이후에 이 아키텍처의 이름을 “Port And Adapter Pattern”이라고 이름을 붙혔지만 많은 사람들이 여전히 육각형 아키텍처라는 이름을 사용하기를 선호합니다. 이 주제에 대한 원본 문서는 여기에서 볼 수 있습니다.
- Tugce Konuklar, Hexagonal (Ports & Adapters) Architecture5
코어번이 작성한 원본 문서는 web.archive.org에서 확인할 수 있습니다. 육각형 아키텍처의 창시자가 직접 작성한 1차자료를 꼭 직접 읽어보세요!
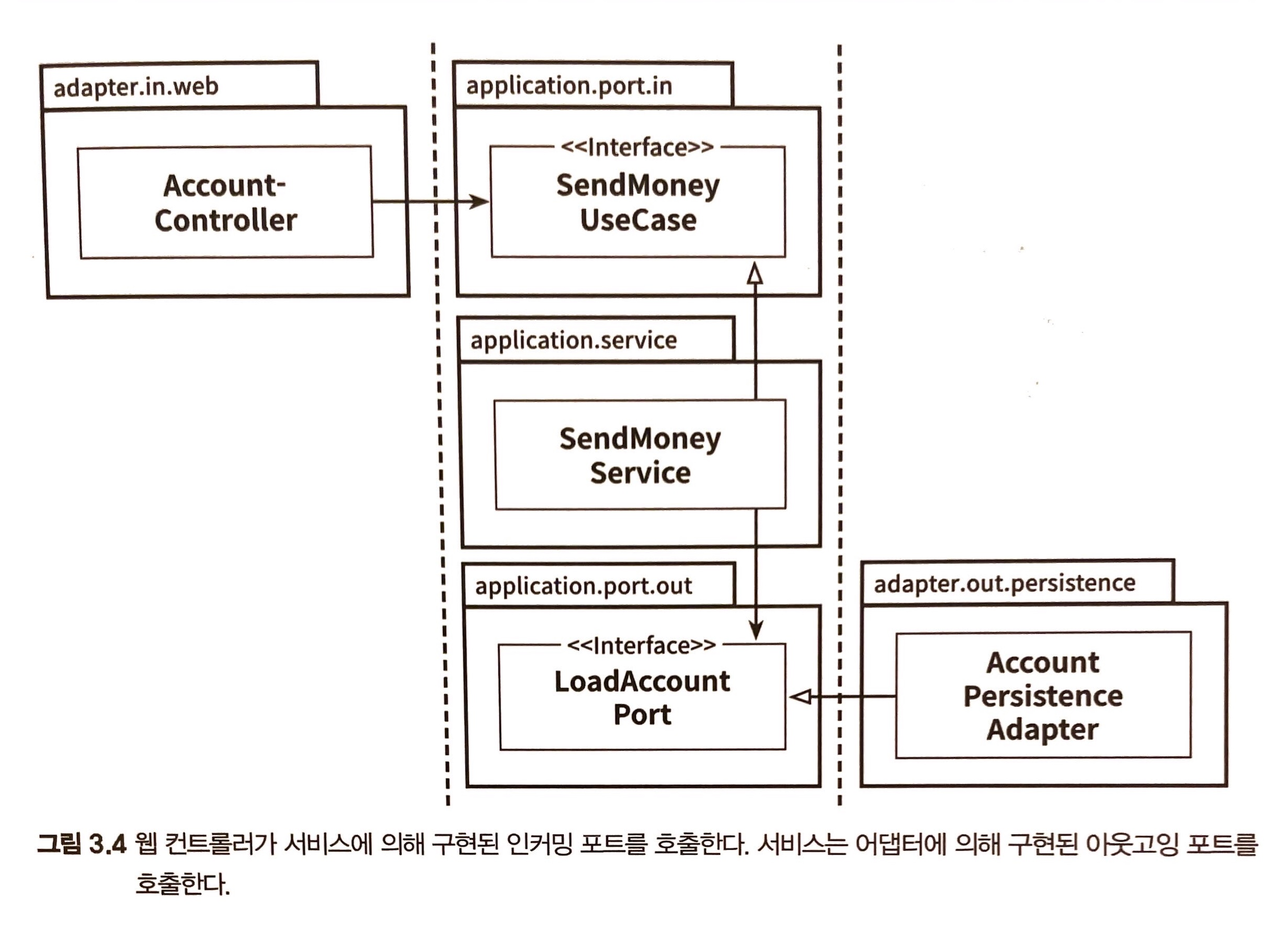
육각형 아키텍처를 사용하는 디렉토리(패키지) 구조
책 『만들면서 배우는 클린 아키텍처』1에서는 마틴의 클린 아키텍처 원칙을 따르면서 코어번의 육각형 아키텍처를 응용해 아래처럼 디렉토리 구조를 제안합니다.

비즈니스 로직은 application 패키지의 SendMoneyService와 domain 패캐지의 Account, Activity에서 수행합니다.
육각형 아키텍처의 궁극적인 목적은 이 3개의 클래스가 세부사항에 오염되지 않도록 보호하는 것입니다. 이를 위해 SendMoneyService 클래스는
SendMoneyUseCase라는 인터페이스를 구현합니다. application 패키지 바깥에서는 SendMoneyService를 직접 의존할 수 없고
포트 역할을 하는 SendMonyUseCase 인터페이스만을 의존할 수 있습니다.
코어번의 글을 읽어보면 ‘primary adapter’와 ‘secondary adapter’라는 개념이 등장합니다. primary adapter는 유스케이스를 사용하는 역할이고,
secondary adapter는 유스케이스에 의해서 사용당하는 역할입니다. adapter/in/web/AccountController가 primary adapter,
adapter/out/persistence 이하의 adapter가 secondary adapter입니다.
사용자가 돈을 보내려고 AccountController를 호출합니다. AccountController는 SendMoneyUseCase 인터페이스를 의존하고 있으므로,
이 인터페이스에 돈을 보내라는 메시지(≒함수 호출)을 보냅니다. 이 인터페이스의 자리에 SendMoneyService가 플러그인 되어있으므로 SendMoneyService 클래스는
메시지를 받아서 돈을 보내는 비즈니스 로직을 수행합니다.
돈을 보냈다는 기록은 메모리상에만 존재하면 안되고 당연히 영구적으로 데이터를 보관할 수 있는 저장장치에 기록을 해야 합니다. SendMoneyServcice는
특정 저장장치와 관련된 클래스 구현체를 의존할 수도 있지만, 위에서 말씀드렸던 것처럼 비즈니스 로직을 담은 클래스는 세부사항에 의존하지 않아야 하므로
SendMoneyService는 LoadAccountPort와 UpdateAccountPort라는 인터페이스를 의존합니다.
이 2개의 포트 인터페이스에 대한 구현체는 AccountPersistenceAdapter 클래스 입니다. SendMoneyService에서 LoadAccountPort와
UpdateAccountPort에 메시지를 보내면 이 포트 인터페이스 자리에 플러그인 되어있는 AccountPersistenceAdapter가 메시지를 받아서
SpringDataAccountRepository를 사용해 송금 기록을 영구적인 저장장치에 기록합니다.
아래의 다이어그램에서 속이 꽉 차있는 화살표 →는 의존관계(혹은 연관관계)를 의미하고, 속이 비어있는 화살표 ⇾는 구현관계(혹은 일반화 관계)를 의미합니다.
application 패키지는 그 자체로서 완결성을 가지고, 이 패키지 바깥(=세부사항)을 의존하지 않습니다. 비즈니스 로직을 담당하는 패키지에
구멍(포트, 인터페이스)을 만들어놓고 외부에서 구현체를 꼽아넣음(plugin)으로서 application 패키지가 세부사항에 오염되지 않도록 순수하게 유지합니다.
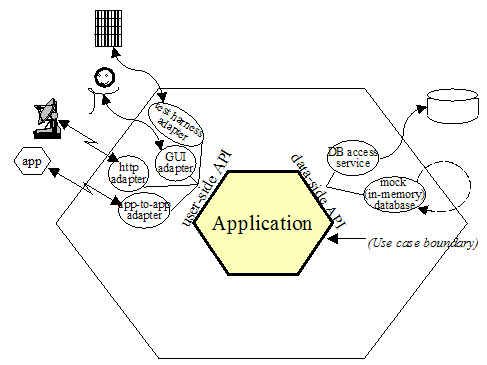
코어번은 이 장황한 설명을 아래와 같은 육각형의 다이어그램을 사용해서 표현했습니다. 더 자세한 이야기가 궁금하다면 꼭 『만들면서 배우는 클린 아키텍처』1를 구매해서 읽어보세요!
우리의 게시판 애플리케이션
챕터 1의 ‘명령줄 인터페이스 애플리케이션’을 구현하면서 저는 아래와 같은 디렉토리 구조를 사용했습니다.
article
├── adapter
│ └── outgoing
│ └── persistence
│ ├── ArticleInMemoryRepository.ts (Class)
│ └── ArticlePersistenceAdapter.ts (Class)
├── application
│ ├── ArticleCommandService.ts (Class)
│ ├── ArticleQueryService.ts (Class)
│ └── port
│ ├── incoming
│ │ ├── ArticleCreateUseCase.ts (Interface)
│ │ ├── ArticleGetUseCase.ts (Interface)
│ │ ├── ArticleListUseCase.ts (Interface)
│ │ ├── ArticleRequest.ts (Type)
│ │ └── ArticleResponse.ts (Type)
│ └── outgoing
│ ├── ArticleLoadPort.ts (Interface)
│ └── ArticleSavePort.ts (Interface)
├── domain
│ ├── Article.ts (Interface)
│ └── ArticleImpl.ts (Class)
└── view
└── cli
├── ArticleCommandViewController.ts (Class)
├── ArticlePrinter.ts (Class)
├── ArticleQueryViewController.ts (Class)
├── MenuPrinter.ts (Class)
└── state-modules
├── State.ts (Interface)
├── View.ts (Type)
├── mobx
│ └── MobxRootState.ts (Class)
├── redux
│ ├── MyStore.ts (Type)
│ └── redux-module.ts (module)
└── vanila
└── StateManager.ts (Class)
Domain
article/domain
├── Article.ts
└── ArticleImpl.ts
도메인에는 Article 인터페이스와 그 구현체인 ArticleImpl이 있습니다. 이렇게 나누어놓은 이유는 JPA(Java Persistence Api)를 사용하면서 생긴 습관인데,
JPA는 엔티티에 @Entity 애노테이션을 붙이도록 강제합니다. JPA의 구현체중 대표격인 Hibernate는 JPA의 애노테이션에 따라 AOP(Aspect Oriented Programming)
방식으로 Proxy를 사용해서 엔티티 클래스에 부가 기능을 붙이게 되는데요, 이 결과로 엔티티 클래스의 인스턴스가 순수한 자바 객체가 아니라 Hibernate에 오염되어버립니다.
때문에 캐싱을 하려고 직렬화/역직렬화를 할 때 순수한 자바 객체(POJO, Pure Old Java Object)가 아니라서 직렬화 과정과 역직렬화 과정이 제대로 이루어지지 않아
JPA 애노테이션이 붙어있는 엔티티의 인스턴스를 캐싱할 수 없었습니다. 그래서 ArticleCached같은 이름으로 순수한 자바 객체를 만들어 캐싱을 하곤 했었습니다.
이 과정에서 ArticleImpl과 ArticleCached 모두 Article 인터페이스를 구현하도록 해서 도메인 영역 바깥에서는 Article 인터페이스를 참조하게 만들었고요.
자바 이야기가 너무 길었네요. 어쨌든 엔티티를 인터페이스와 구현체로 나누어서 구현해놓으면 언젠가 도움이 됩니다. 혹시 모르죠, 우리 튜토리얼에서도 TypeORM같은 ORM 프레임워크를 사용해볼 기회가 있을지…?
Application
article/application
├── ArticleCommandService.ts (Class)
├── ArticleQueryService.ts (Class)
└── port
├── incoming
│ ├── ArticleCreateUseCase.ts (Interface)
│ ├── ArticleGetUseCase.ts (Interface)
│ ├── ArticleListUseCase.ts (Interface)
│ ├── ArticleRequest.ts (Class)
│ └── ArticleResponse.ts (Class)
└── outgoing
├── ArticleLoadPort.ts (Interface)
└── ArticleSavePort.ts (Interface)
domain 디렉토리와 application 디렉토리를 합쳐서 광의(廣義)의 도메인 영역이라고 할 수 있습니다. 오직 비즈니스만을 위한 코드가 존재하는,
세부사항2에 오염되지 않도록 순수하게 유지해야 하는 영역입니다.
제일 먼저 봐야 하는 부분은 port/incoming의 유스케이스 인터페이스들입니다. 저는 아티클의 생성, 개별조회, 목록조회를 각각
ArticleCreateUseCase, ArticleGetUseCase, ArticleListUseCase라는 이름의 인터페이스로 만들었습니다.
개별 기능마다 각각 UseCase라는 단어를 붙였습니다 (톰 홈버그1를 따라서). article/application 디렉토리 바깥에서 위 기능들을 사용하려면
기능의 구현체를 직접 의존하지 말고 유스케이스 인터페이스만을 의존해야 합니다.
코어번은 유스케이스에 대해서 아래와 같이 말했습니다.
육각형 아키텍처 패턴을 선호되는(the preferred way, 뭐라고 번역해야 좋을까요..) 유스케이스 작성법을 강화하기 위해 사용하면 유용하다.
흔히 저지르는 실수는 개별 포트의 바깥 부분에서 사용하는 기술과 밀접하게 연결된 지식을 유스케이스에 포함하는 것이다. 이런 (포트 바깥쪽 기술에 대한 지식을 포함하는) 유스케이스들은 길고, 읽기 어럽고, 지루하고, 불안정하고, 유지보수 비용이 많이 드는 것으로 악명을 떨쳐왔다.
‘포트와 어댑터 아키텍처’를 이해한다면, 우리는 유스케이스들이 애플리케이션 경계(육각형의 안쪽)에 작성해야 한다는 것을 알 수 있다. 이렇게 함으로써 외부 기술과 관계 없이 애플리케이션에 의해 지원되는 기능과 이벤트를 지정(specify)할 수 있다. 이런 유스케이스들은 짧고, 읽기 쉽고, 유지보수 비용이 적게 들고, 시간이 지나도 안정적이다.
유스케이스와 구현체
ArticleCommandService는 ArticleCreateUseCase를, ArticleQueryService는 ArticleListUseCase, ArticleGetUseCase를 구현합니다.
어떤 기준으로 구현체를 나눴을까요? 두구두구.. 바로 ‘상태’의 변경 여부입니다. 모든 비극은 상태를 변경하면서 발생합니다.
명령 질의 분리
상태를 변경하는 부분과 상태를 변경하지 않고 데이터를 조회하는 부분을 분리해야 함은 1988년에 버트런드 마이어가 처음 제안했습니다.
그는 이 제안에 CQS(Command Query Separation)이라는 이름을 붙였습니다. 짧게 요약하자면, 상태를 변경하는 함수는 return값이 없고,
return값이 있는 함수는 상태를 변경하면 안된다는 것입니다.
함수형 프로그래밍을 공부하다 ‘불변성Immutability’ 개념을 만나면 Function과 Procedure라는 이름으로 함수의 종류를 나눠서 설명하는 것을
볼 수 있는데, 이 역시 버트런드 마이어가 제안한 단어들입니다.
버트런드 마이어는 이미 1980년대에 CQS가 분산 컴퓨팅으로 이어질 수 있다고 예언했고, CQS는 2010년대에 들어서 CQRS(Command Query Responsibility Segregation)라는 이름으로 부활합니다.
CQRS라는 단어는 2009년 언저리에 등장했지만 이 단어의 등장에 대한 합의(consensus)는 이루어지지 않았다. 2012년에 Fitzgerald는 CQRS를 정의했다: “애플리케이션이나 시스템의 책임을 쓰기Writing과 읽기Reading로 분리하는데, 객체 수준이 아니라 전체적인 아키텍처 수준에서 분리하는 것”
Fitzgerald는 CQRS와 CQS의 연관성을 CQRS의 정의에 분명하게Clearly 포함했다 (객체 수준=CQS). CQRS는 CQS를 객체 수준의 디자인이 아니라 애플리케이션 수준의 디자인에 채택한 것이다. 이는 아키텍처에 대해서 몇가지의 함의를 갖는다.
지금까지 말씀드린 CQS와 CQRS는 모두 위링크의 논문에서 가져왔습니다. 더 자세한 내용이 궁금하시다면 다음 글을 참고하세요: 명령 질의 책임 분리의(Command Query Responsibility Segregation, CQRS)의 근본을 찾아서
인터페이스 분리 원칙(ISP, Interface Segregation Principle)
ArticleQueryService라는 구현체는 두 개의 인터페이스 ArticleGetUseCase, ArticleListUseCase를 구현합니다.
개별 조회와 목록 조회를 하나의 인터페이스에 선언하지 않고 두 개의 인터페이스로 나눈 이유는 인터페이스 분리 원칙(ISP)을 지키기 위함입니다.
개별 조회와 목록 조회라는 두 개의 기능을 하나의 인터페이스로 선언하면 개별 조회만 필요한 곳에서도 목록 조회 기능에 대한 의존성이 발생합니다. 실제로는 목록 조회 기능의 변경에 대해서 아무런 영향이 없더라도 객체 의존관계로만 보면 목록 조회 기능을 의존하는 것처럼 보입니다.
목록 조회와 개별 조회 기능 하나 하나가 비대해져서 두 개의 구현체로 쪼개야 하는 경우에도 골치아파집니다. 두 기능을 합친 인터페이스를 의존하는 모든 곳에 변경사항이 발생해야 하니까요. 처음부터 ISP를 지켜서 두 개의 인터페이스로 분리했다면 객체 의존관계에서도 어떤 기능을 의존하는지 명확하게 파악할 수 있고, 구현체를 두 개로 만들지 하나로 만들지에 대한 선택을 자유롭게 할 수 있습니다.
단일 책임 원칙 (SRP, Single Responsibility Principle)
그래서 ArticleQueryService를 하나로 놔둬도 된다는 말인가요 두 개로 쪼개야 한다는 말인가요? 저는 이 부분은
취사선택(trade-off)의 문제라고 생각합니다.
‘조회’를 하나의 책임으로 본다면 클래스를 하나만 만들어도 되고, 개별 조회와 목록 조회로 책임을 나누어서 생각한다면 두 개의 클래스도 나누어도 되고요.
클래스를 하나만 만들면 코드량이 줄어들어서 좋고, 클래스를 두 개로 나누게 되면 단일 책임 원칙을 더 작은 단위로 지킬 수 있어서 좋습니다.
그러면 굳이 Command와 Query도 나누지 않고 하나의 ArticleService에서 3개의 인터페이스를 구현하면 안되나요? 당연히 됩니다! 하지만 저는 존경하는
버트런드 마이어를 위해서 그의 CQS를 객체수준까지 지키려고 노력하는 편입니다. 프로그래밍의 모든 비극은 상태를 변경하면서 발생하기 때문에 상태의 변경 여부에
따라 코드를 나누어 놓으면 마음이 편합니다.
클래스 나누기에 대한 더 깊은 고민은 기계인간 이종립님의 블로그를 참고하세요: (기록) 한 개의 메소드만 갖는 계층형 컨트롤러/서비스 패키지 스타일
상태를 변경할 때 발생하는 비극
상태를 변경하지 않으면 세상은 한결 수월해집니다. 그런 세상이 어딨냐고요? 혹시 git이라고 들어보셨나요?
…
이벤트 소싱 event sourcing에 깔려 있는 기본 발상이 바로 이것이다. 이벤트 소싱은 상태가 아닌 트랜잭션을 저장하자는 전략이다. 상태가 필요해지면 단순히 상태의 시작점부터 모든 트랜잭션을 처리한다.
물론 지름길을 택할 수도 있다. 예를 들어 매일 자정에 상태를 계산한 후 저장한다. 그 후 상태 정보가 필요해지면 자정 이후의 트랜잭션만을 처리하면 된다.
이제 이 전략에 필요한 데이터 저장소에 대해 생각해보자. 아마 저장 공간이 많이 필요할 것이다. 실제로 오프라인 데이터 저장소는 급격하게 증가하여 이제는 수 테라바이트도 작다고 여기는 시대다. 따라서 우리는 저장 공간을 충분히 확보할 수 있다.
더 중요한 점은 데이터 저장소에서 삭제되거나 변경되는 것이 하나도 없다는 사실이다. 결과적으로 애플리케이션은 CRUD가 아니라 그저 CR만 수행한다. 또한 데이터 저장소에서 변경과 삭제가 전혀 발생하지 않으므로 동시 업데이트 문제 또한 일어나지 않는다.
저장 공간과 처리 능력이 충분하면 애플리케이션이 완전한 불변성을 갖도록 만들 수 있고, 따라서 완전히 함수형으로 만들 수 있다.
이 이야기가 여전히 터무니없게 들린다면, 소스 코드 버전 관리 시스템이 정확히 이 방식으로 동작한다는 사실을 떠올려 보면 도움이 될 것이다.
- 로버트 C. 마틴, 송준의. 클린 아키텍처. 서울: 인사이트, 2019. p59
제가 보기엔 컴퓨터 세상의 모든 비극은 상태를 변경하면서 발생합니다. 계약에 의한 설계에서도 상태 변경이 만들어내는 비극을 발견할 수 있습니다.
조영호님은 책 『오브젝트』의 부록에서 계약에 의한 설계를 객체의 협력 관점에서 아래와 같이 설명했습니다.
- 협력에 참여하는 각 객체는 계약으로부터 이익을 기대하고 이익을 얻기 위해 의무를 이행한다.
- 협력에 참여하는 각 객체의 이익과 의무는 객체의 인터페이스 상에 문서화된다.
사전조건, 사후조건, 불변식:
- 사전조건(precondition): 메서드가 호출되기 전에 만족해야 하는 조건. 클라이언트의 의무
- 사후조건(postcondition): 메서드가 실행된 후에 클라이언트에게 보장해야 하는 조건. 서버의 의무
- 불변식(invariant): 항상 참이라고 보장되는 서버의 조건. 메서드 실행중에는 불변식을 만족시키지 못할 수도 있지만 메서드를 실행하기 전이나 종료된 후에 불변식은 항상 참이어야 한다.
- 조영호. 부록A: 계약에 의한 설계, 오브젝트. 파주: 위키북스, 2019,
사전조건, 사후조건, 불변식이 검사하는게 뭘까요? 상태입니다(…너무 당연한가요). 불변식은 함수(≒메서드)가 아무런 외부효과(=상태변화)를 만들지 않는다면 검사할 필요조차 없습니다. 실행한 함수 바깥에서는 아무 일도 일어나지 않았으니까요.
불행히도 함수가 외부효과를 일으킨다면 불변식에 신경을 써야합니다. 특히 메서드 실행중에는 불변식을 만족하시키지 못할 수도 있다는 부분을 주목해야 합니다. 어떤 함수가 실행중인데 누군가 다른 함수를 실행해서 불변식을 깨버리면 어떻게 될까요? 불변식이 깨진 상태에서 실행한 함수의 올바른 동작을 보장할 수 있을까요? 이 질문은 데이터 무결성이 매우 중요한 데이터베이스의 세계의 트랜잭션 격리 레벨과 이어집니다.
멀티쓰레딩을 지원하는 데이터베이스의 트랜잭션 격리 레벨이 serializable이 아닌 경우 데이터베이스는 불변식이 만족되지 않는 상태의 데이터를 바탕으로 작업을 진행할 가능성이 있습니다. 멀티쓰레딩 환경에서 데이터베이스 트랜잭션의 정상 작동6을 보장하면서도 성능 향상을 위해 snapshot isolation이라는 방식을 사용합니다. 정말 쉽고 부정확하게 설명하자면, 트랜잭션을 시작하기 전에 데이터베이스 상태를 복제하고(=snapshot) 이를 바탕으로 작업을 진행한 뒤 트랜잭션을 끝내면서 변경사항을 원본 DB에 반영하는 방식입니다. 복제된 상태인 snapshot은 다른 트랜잭션이 볼 수 없기 때문에 트랜잭션이 작업을 수행할 때는 문제가 없지만, 원본 DB에 변경사항을 반영하면서 문제가 발생합니다.
대표적인 예시가 Doctor Duty 문제인데요, 이 문제는 멀티쓰레딩 환경에서 snapshot isolation 방식을 사용하면서도 트랜잭션의 정상 작동을 완벽하게 보장하는 격리 레벨인 serializable isolation이 가능하다는 것을 증명한 기념비적인 논문인 Serializable Isolation for Snapshot Databases7에서 사용한 예시입니다.
Doctor Duty 문제는 Cockroach DB의 Serializable Transaction8 문서에서 친절하게 설명하고 있습니다.
시나리오
- 의사는 휴게 대기(온콜, on call) 교대근무 일정을 관리할 수 있는 애플리케이션으로 관리할 수 있다.
- 최소한 한 명의 의사는 휴게 대기를 해야한다는 규칙이 있다.
- 두 명의 의사가 특정 교대근무에 대기 중이고, 이들이 거의 동시에 교대근무에 대한 휴가를 요청하려고 한다.
- Postgres DB의 기본 트랜잭션 격리 레벨인
READ COMMITTED에서는 write skew 이상(anomaly)이 발생해 두 의사 모두 성공적으로 휴가를 예약하고 병원에 휴게 대기 교대근무를 하는 의사가 한 명도 남지 않는 상황이 발생한다.- Cockroach DB의
SERIALIZABLE격리 레벨을 사용하면 write skew를 예방할 수 있다. 한 명의 의사만 휴가를 갈 수 있기 때문에 생명을 구할 수 있다 (만세!).
논문에서는 어떻게 write skew를 예방하고 serializable 격리 수준을 만족할까요? 저는 마법이라고 생각하고 있…지는 않지만 이 정도면 석사 수준의 이야기라고 생각하기 때문에 학사 학위만 있는 저는 더 이상 입을 열지 않겠습니다. 어쨌든, 상태를 변경하는 일은 이렇게나 위험합니다. 의사가 모두 휴가를 가버려서 살릴 수도 있는 생명을 잃게 되는 비극이 발생한다구요!
머신러닝 같은 특수한 경우를 제외하고 컴퓨터 세상에서 99.99%의 정확도는 허용할 수 없습니다. 엄청나게 높은 정확도같지만, 100만번의 요청이 온다면 무려 100번이나 비정상적으로 작동한다는 말이기 때문입니다. 주위 개발자가 맨날 최악을 생각하고 시시콜콜한 것까지 모두 신경쓴다고요? 직업병이니 너그럽게 이해해주세요…
데이터 캐리어 (Data Carrier)
port/incoming 디렉토리에는 ArticleRequest와 ArticleResponse 타입이 있습니다. 이 타입은 유스케이스 인터페이스가 application
디렉토리 바깥 세상과 소통하기 위해 매개변수와 리턴값으로 사용합니다. 도메인 엔티티인 Article를 애플리케이션 바깥으로 내보내지 않도록 제한해서
애플리케이션의 경계를 확실하게 해주는 역할을 합니다. 다만 편의를 위해서 타입스크립트의 type 예약어로 선언했습니다. 좀 더 강력하게 Article을 보호하기
위해서 타입 대신 클래스로 만들어도 좋습니다.
무조건 Article이 애플리케이션 바운더리 바깥으로 빠져나가면 안되는 걸까요? 무조건은 없습니다. 소수의 개발자가 적은 양의 코드베이스에서 개발하고
유지보수하는 상황이라면 뭔들 불가능할까요, 그들간의 일관성만 맞추면 됩니다. 하지만 다수의 개발자가 투입된 큰 프로젝트에서는 이 규칙들을 엄격하게 지키는 편이
좋다고 생각합니다.
얘네들 DTO(Data Transfer Object) 아니에요?
DTO가 뭘까요? 단순하게 번역하면 데이터 전송 객체인데… 데이터라는건 알겠는데 전송은 뭐고 객체는 또 뭘까요?
마틴 파울러는 DTO를 다음과 같이 설명합니다.
원격 퍼사드(Remote Facade)같은 원격 인터페이스와 협업을 한다면 한 번 한 번의 요청에 비용이 많이 든다. 결과적으로 요청 횟수를 줄일 필요가 있고, 이는 한 번의 요청에 많은 데이터를 전송해야 함을 의미한다. 많은 수의 파라미터를 사용하는 것도 방법이 될 수 있다. 그러나 이 방법으로 프로그램을 작성하기엔 곤란한 경우가 있다 - 자바같이 하나의 값만 리턴할 수 있는 언어에서는 불가능한 방법이다.
When you’re working with a remote interface, such as Remote Facade (388), each call to it is expensive. As a result you need to reduce the number of calls, and that means that you need to transfer more data with each call. One way to do this is to use lots of parameters. However, this is often awkward to program - indeed, it’s often impossible with languages such as Java that return only a single value.
해결책은 요청에 필요한 모든 데이터를 담을 수 있는 데이터 전송 객체(Data Transfer Object, DTO)를 만드는 것이다. 연결(connection)을 가로질러야 하기 때문에 데이터 전송 객체는 직렬화가 가능해야 한다. 보통 서버 측에서 DTO와 도메인 객체 사이의 데이터 전송을 담당하는 어셈블러를 사용한다.
The solution is to create a Data Transfer Object that can hold all the data for the call. It needs to be serializable to go across the connection. Usually an assembler is used on the server side to transfer data between the DTO and any domain objects.
- Martin Fowler, “P of EAA: Data Transfer Object”. 2022년 3월 19일 접근. https://martinfowler.com/eaaCatalog/dataTransferObject.html
DTO의 전송(Transfer)는 주로 네트워크 통신과 관련(원격 퍼사드)된 의미로 사용한다고 볼 수 있습니다. ArticleRequest, ArticleResponse는
원격 요청이 아니라 애플리케이션 내부에서 데이터를 옮기기 위해 사용하는 타입이니 ‘전송’이라는 단어는 어울리지 않습니다. 그럼 데이터 객체(Data Object)라고
부르면 어떨까요?
이것 또한 애매한 것이… ‘객체’라는 단어에 이미 데이터가 포함되어 있을 뿐더러, 과연 이 데이터 뭉치를 객체라고 부를 수 있는지도 애매하기 때문입니다. 객체 지향 프로그래밍의 선구자 엘런 케이는 ‘객체 지향’이라는 단어의 탄생에 대해서 이야기하면서 다음과 같이 말했습니다.
나는 객체들을 생물학적 세포나 네트워크의 개별 컴퓨터라고 생각했다. 이들은 오직 메시지로서만 소통이 가능하다 (그래서 메시지를 처음부터 도입했다 – 메시지를 프로그래밍 언어로 효과적으로 사용하는 방법을 알게 되기까지 시간이 조금 걸렸지만).
- I thought of objects being like biological cells and/or individual computers on a network, only able to communicate with messages (so messaging came at the very beginning – it took a while to see how to do messaging in a programming language efficiently enough to be useful).
나는 데이터를 없애버리고 싶었다. B5000은 믿기지 않는 하드웨어 아키텍처로 이것(데이터 없애기)을 거의 해냈다. 나는 세포/온전한-컴퓨터 은유가 데이터를 없앨 수 있고, “<-“는 그저 또 다른 메시지 토큰일 뿐이라는 것을 깨달았다. (이것을 깨닫기 까지 시간이 꽤 걸렸는데, 이 기호가 함수와 프로시저의 이름을 나타내는 것이라고 생각했기 때문이다)
- I wanted to get rid of data. The B5000 almost did this via its almost unbelievable HW architecture. I realized that the cell/whole-computer metaphor would get rid of data, and that “<-“ would be just another message token (it took me quite a while to think this out because I really thought of all these symbols as names for functions and procedures.
- Stefan L. Ram, Berlin. “Dr. Alan Kay on the Meaning of ‘Object-Oriented Programming’”. Stefan L. Ram, Berlin, Germany., 2003년 7월 23일. https://www.purl.org/stefan_ram/pub/doc_kay_oop_en.
위 링크는 창시자 앨런 케이가 말하는, 객체 지향 프로그래밍의 본질에서 찾았습니다.
엘런 케이는 객체 하나 하나가 온전한 기능을 하는 작은 컴퓨터라고 생각했습니다. ArticleRequest, ArticleResponse는 기능 하나 없는 그저 데이터
뭉치이기 때문에 데이터 객체(Data Object)라고 부르기엔 너무 과하니 객체라는 이름도 빼고 데이터라고 부르면 될 것 같네요. 하지만 데이터… 라고만 부르기엔
그 뜻이 너무 광범위하니, 이일민(토비)님이 제안하신 데이터 캐리어(Data Carrier)라고 부르겠습니다.
정의도 혼란스런 DTO 그만쓰자. Data Carrier라고 불러라. 줄여서 DC.
“이 경우엔 캐리어 하나 만들어서 날리시죠”
이일민, 2022년 3월 13일, https://www.facebook.com/tobyilee/posts/10222914608868299
심지어 ArticleRequest, ArticleResponse는 인스턴스화할 수 있는 클래스가 아니라 타입일 뿐이니까.. 데이터 캐리어 타입이라고 부르면 되겠습니다.
값 객체(VO, Value Object)는 어떨까요? 값 객체는 이미 에릭 에반스의 『도메인 주도 개발』4에서 특정한 의미로 쓰이고 있는 단어니까 여기서는 다른 단어를 사용하게는게 좋겠습니다. 마틴 파울러도 값 객체에 대해서 한 마디 했습니다: https://martinfowler.com/eaaCatalog/valueObject.html
Outgoing 포트
port/outgoing 디렉토리에는 ArticleLoadPort, ArticleSavePort 인터페이스가 있습니다. ArticleLoadPort는 유스케이스와는 다르게
하나의 인터페이스에서 개별 조회와 목록 조회를 모두 선언했습니다. 이유는.. 그냥 제 맘입니다.
이 포트들의 역할은 이름을 보시면 아시겠지만 데이터 저장소에서 Article을 불러오는 것입니다. 포트들은 유스케이스의 구현체에서 사용하게 됩니다.
위에서 이야기한 secondary adapter가 구현해야할 인터페이스가 이 포트들입니다.
구현체를 직접 의존하지 않고 인터페이스를 사용하는 이유는, application 디렉토리의 의존성 화살표가 다른 디렉토리로 빠져나가지 않도록 제한하기 위함입니다.
그리고 인터페이스와 구현체를 분리함으로써 여러 개의 구현체를 갈아끼우면서 저장소를 자유롭게 선택할 수 있다는 장점도 있습니다.
Adapter
article/adapter
└── outgoing
└── persistence
├── ArticleInMemoryRepository.ts (Class)
└── ArticlePersistenceAdapter.ts (Class)
ArticlePersistenceAdapter는 ArticleLoadPort, ArticleSavePort를 구현합니다. 어댑터라는 이름을 가진 만큼 이 클래스는 다른 클래스에게
동작을 위임하는 역할을 합니다. 데이터의 Load과 Save는 ArticleInMemoryRepository 클래스에서 수행합니다.
import { ArticleImpl } from "../../../domain/ArticleImpl";
export class ArticleInMemoryRepository {
constructor(private records: Record<number, ArticleImpl> = {}) {}
public save = (article: ArticleImpl): void => {
this.records[article.id] = article;
};
public findById = (id: number): ArticleImpl | undefined => this.records[id];
public findAll = (): ArticleImpl[] => Object.values(this.records);
}
ArticleInMemoryRepository는 자바스크립트의 기본 객체를 사용해서 ArticleImpl을 메모리에 보관하는 클래스입니다.
애플리케이션이 꺼지더라도 데이터를 보존하고 싶으면 어떻게 하면 될까요? 운영체제에서 기본으로 제공하는 파일 시스템을 이용해도 되고, 관계형 데이터베이스를
사용해도 되고, NoSQL 데이터베이스를 사용해도 되고, redis같은 In-Memory 데이터베이스를 사용해도 되고, Strapi같은 headless CMS를 띄워서
http 요청을 사용해도 됩니다. 해당 기술을 사용하는 Repository를 구현하고 어댑터와 연결만 해주면 끝입니다. application 디렉토리는
adapter 디렉토리를 의존하지 않기 때문에 데이터가 어디에 어떻게 저장되고 불러와지는지(=세부사항) 전혀 모릅니다.
모르는게 약입니다. 정보를 제한하는만큼 유연한 설계를 할 수 있습니다. 아이러니하게도 정보 기술(IT) 분야의 설계를 잘 하기 위해서는 정보를 차단해야 합니다. 프로그래밍 언어도 사용자에게 정보를 제한하는 방식으로 발전해왔습니다.
천공카드로 프로그래밍을 하던 시절에는 프로그래머가 하드웨어에 대한 모든 정보와 권한을 가질 수 있었습니다. 정보와 권한이 따르는 만큼 천공카드 프로그래밍은 고려해야 할 것들이 무지막지하게 많았고, 0과 1로 만들 수 있는 무궁무진한 경우의 수 때문에 프로그램의 크기가 조금만 커져도 유지보수하기가 어려웠습니다.
이후에 어셈블러가 등장하면서 0과 1대신 영어 단어로 만들어진 어셈블리어가 탄생했고 사정이 조금 나아졌지만, 숫자와 영어 단어를 1:1 매핑한 것과 진배없었기 때문에 역시 프로그래머가 고려해야 할 정보의 양은 산더미 같았습니다.
다음엔 포트란(Fortran), 리습(LISP), 코볼(Cobol) 같은 언어와 언어의 구현체인 컴파일러가 등장하면서 사정은 훨씬 나아졌습니다. 어셈블리어보단 훨씬 영어와 가까워졌고, 언어 사용자들은 어셈블리어로 코딩하던 시절보다 권한은 줄었지만 덕분에 고려해야할 정보의 양이 줄어들었습니다.
계속 이런식입니다. 특정한 상황을 가정해서 경우의 수를 확 줄인 대신 매우 간단한 사용법을 제공하는 도메인 특화 언어(Domain Specific Language, DSL)도 이 흐름 안에 있습니다.
마틴은 책 『클린 아키텍처』3 에서 구조적, 객체지향, 함수형 패러다임을 ‘권한의 박탈’ 관점으로 설명합니다.
내가 이들 세 가지(구조적, 객체지향, 함수형) 프로그래밍 패러다임을 소개하면서 신중하게 설정한 패턴이 보일 것이다. 각 패러다임은 프로그래머에게서 권한을 박탈한다. 어느 패러다임도 새로운 권한을 부여하지 않는다. 각 패러다임은 부정적인 의도를 가지는 일종의 추가적인 규칙을 부과한다. 즉, 패러다임은 무엇을 해야 할지를 말하기보다는 무엇을 해서는 안 되는지를 말해준다.
이러한 논의를 바라보는 또 다른 방법은 각 패러다임이 우리에게서 무언가를 빼앗는다는 사실을 인지하는 것이다. 세 가지 패러다임은 각각 우리에게서 goto문, 함수 포인터, 할당문을 앗아간다. 우리에게서 가져갈 수 있는게 더 남아 있는가?
아마 없을 것이다. 따라서 프로그래밍 패러다임은 앞을도 딱 세 가지밖에 없을 것이다. 최소한 부정적인 의도를 가진 패러다임으로는 이 세 가지가 전부일 것이다. 이 밖에 다른 패러다임이 없다는 또 다른 증거로는 이들 패러다임이 1958년부터 1968년에 걸친 10년 동안 모두 만들어졌다는 사실이다. 이후로 수십 년이 지났지만, 새롭게 등장한 패러다임은 없다.
- 로버트 C. 마틴, 송준의. 클린 아키텍처. 서울: 인사이트, 2019. p27
선언형 언어 (Declarative Language)
저는 요새는 선언형으로 프로그램을 작성하거나 언어를 만드는 경우가 많아졌다고 느낍니다. 선언형은 절차형과 대척점에 있는 개념입니다. 절차형이 ‘어떻게How’를 작성한다면, 선언형은 ‘무엇을What’을 작성합니다. 행동을 기술하는 대신 원하는 것을 기술합니다. 함수형 패러다임도 선언형의 일종이라고 볼 수 있습니다.
회사 대표님이 아래와 같은 요구사항을 만족하는 만족하는 함수를 만들어달라고 개발팀에게 부탁했다고 가정해봅시다.
[
['name', 'age', 'gender'],
['팽대표', 34, '남'],
['홍길동', 50, '남'],
]
// 위 배열을 아래 Object로 변환하고 싶다...
[
{
name: 팽대표,
age: 34,
gender: 남
},
{
name: 홍길동,
age: 50,
gender: 남
},
]
이를 절차형과 함수형으로 구현해보겠습니다.
type Input = Array<Array<string | number>>;
type Output = Record<string, string | number>;
const input: Input = [
["name", "age", "gender"],
["팽대표", 34, "남"],
["홍길동", 50, "남"],
];
const expected = [
{
name: "팽대표",
age: 34,
gender: "남",
},
{
name: "홍길동",
age: 50,
gender: "남",
},
];
const csvToObjectProcedural = (csv: Input): Output[] => {
assert(csv.length > 0);
const header = csv[0];
const objs: Output[] = [];
for (let i = 1; i < csv.length; i++) {
const row = csv[i];
const obj: Output = {};
for (let k = 0; k < header.length; k++) {
obj[header[k]] = row[k];
}
objs.push(obj);
}
return objs;
};
const csvToObjectFunctional = (csv: Input): Output[] => {
assert(csv.length > 0);
const [header, ...rows] = csv;
return rows.map((row) =>
row.reduce<Output>(
(prev, curr, index) => ({
...prev,
[header[index]]: curr,
}),
{}
)
);
};
assert(JSON.stringify(csvToObjectProcedural(input)) === JSON.stringify(expected));
assert(JSON.stringify(csvToObjectFunctional(input)) === JSON.stringify(expected));
절차형 구현인 csvToObjectProcedural 함수는 매개변수인 csv를 순회하기 전에 리턴값을 보관할 objs 배열을 선언합니다. 그리고 csv를 순회하면서
Output 객체를 만들어서 objs 배열에 push합니다. Output 객체를 만들기 위해서도 csv의 1번 인덱스 이상을 순회하면서 obj 객체에
키와 값을 채워넣습니다.
함수형 구현인 csvToObjectFunctional 함수는 매개변수인 csv를 일단 header와 rows로 나눕니다. 이는 함수형 프로그래밍에서
head와 tail을 나누어서 배열을 처리하는 방식을 차용했습니다. 이후에는 map과 reduce라는 미리 정의되어 있는 연산자를 사용해서 작업을 진행합니다.
배열을 ‘어떻게’ 순회할지 작성하지 않고, 배열을 순회해서 ‘무엇을’ 얻을지에 대해서 작성합니다.
‘어떻게’ 순회할지 작성하는 절차형 코드에서는 for 반복문의 시작 인덱스를 잘못 설정한다든지, 종결조건을 잘못 설정한다든지 하는 실수가 발생할 수 있습니다. 누가 그런 실수를 하냐고요? 저요… 이런 사소한 실수는 큰 실수들보다 오히려 발견하는데 오랜 시간이 걸리는 것은 물론 덤으로 자괴감까지 선사합니다 하…
map과 reduce 연산자는 절차형의 for 반복문보다는 할 수 있는 것들이 적습니다. 예를 들어서 배열의 element를 하나씩 건너뛰어서 홀수만 접근한다든지,
특정 조건을 만족할 때 반복을 끝낸다든지. for 반복문보다는 제한된 기능을 제공하지만, 사용자는 미리 잘 추상화된 연산자를 사용함으로써 인덱스나 종결 조건에
대한 권한과 책임에서 자유로워집니다.
제가 2018년에 리액트로 form을 개발할 때는 redux-form을 사용했습니다. 입력값에 대한 검증은 사용자가 직접 구현해야 했습니다: https://redux-form.com/6.5.0/examples/fieldlevelvalidation/
import React from 'react'
import { Field, reduxForm } from 'redux-form'
const required = value => value ? undefined : 'Required'
const maxLength = max => value =>
value && value.length > max ? `Must be ${max} characters or less` : undefined
...
2020년엔 Formik과 Yup을 사용했습니다. Yup은 Formik에서 값 검증을 할 때 사용을 권장하는 라이브러리입니다.
import React from 'react';
import { Formik, Form, Field } from 'formik';
import * as Yup from 'yup';
const SignupSchema = Yup.object().shape({
firstName: Yup.string()
.min(2, 'Too Short!')
.max(50, 'Too Long!')
.required('Required'),
lastName: Yup.string()
.min(2, 'Too Short!')
.max(50, 'Too Long!')
.required('Required'),
email: Yup.string().email('Invalid email').required('Required'),
});
redux-form에서는 검증용 함수를 직접 구현해야 했다면, Formik에서는 Yup을 사용해서 검증 요구사항을 선언형으로 작성할 수 있습니다. Yup 사용자는 값을 ‘어떻게’ 검증할지 작성하는게 아니라 ‘무엇을’ 검증할지 작성합니다.
Flutter를 사용하면 UI를 선언형으로 작성할 수 있습니다: https://docs.flutter.dev/get-started/flutter-for/declarative 여기서도 ‘어떻게’로부터 ‘무엇을’으로의 이동을 발견할 수 있습니다.
// Imperative style
b.setColor(red)
b.clearChildren()
ViewC c3 = new ViewC(...)
b.add(c3)
// Declarative style
return ViewB(
color: red,
child: ViewC(...),
)
IaC(Infrastructure as Code) 도구인 Terraform은 자체적인 언어인 Terraform Language을 사용합니다. 이 언어도 역시 선언형입니다.
The Terraform language is declarative, describing an intended goal rather than the steps to reach that goal.
- Overview - Configuration Language | Terraform by HashiCorp
resource "aws_vpc" "main" {
cidr_block = var.base_cidr_block
}
제가 처음으로 제대로 사용한 선언형 언어는 SQL(Structured Query Language)입니다. 절차형 패러다임에 절여진 뇌로 SQL를 처음 만났을 때, 이미 작성되어 있는 코드를 읽기에는 편했지만 막상 제가 작성하려고 하니까 하나도 모르겠더라고요. 뇌를 절차형 용액에서 건져내 선언형을 받아들일 때까지 시간이 오래 걸렸습니다. SQL도 마찬가지로 DB에게 ‘어떻게’ 대신 ‘무엇을’을 요청합니다. 어떻게 데이터를 가져오거나 변경할지는 DBMS(Database Management System) 맘대로입니다.
SELECT id, subject, content FROM article;
절차형에서 선언형으로의 이동은 구현체밖에 없는 세상에서 인터페이스와 구현체가 분리된 세상으로의 이동이라고도 말할 수 있습니다. 구현체와 사용자 사이에 선언형 언어라는 계층을 만들어서 여백을 확보합니다. 이 여백때문에 사용자는 권한과 책임에 제약을 받지만 더 쉽게 구현체를 사용할 수 있고, 구현체는 변경사항이 언어에 영향을 미치지 않는 선에서 자유롭게 바뀔 수 있습니다.
incoming 어댑터는 어디갔어요?
글쎼요.. 어디갔을까요? 육각형 아키텍처를 사용하는 디렉토리(패키지) 구조로 다시 올라가보면
adapter/in/web/AccountController라는 incoming 어댑터를 확인할 수 있습니다. 명령줄 인터페이스 애플리케이션이 아니라 웹 애플리케이션이었다면
저도 이 형태를 따라 컨트롤러를 구현했겠지만, 저는 이번에 구현하면서 View와 Controller의 분리가 힘들어서 그냥 ViewController를 만들어버렸습니다.
명령줄로 사용자 입력을 받는 부분과 애플리케이션을 제어하는 컨트롤러를 분리하기가 어려웠습니다. 분명 더 좋은 구조가 있을 것 같은데, 여러분은 어떻게
구현하셨을지 궁금합니다.
View
article/view
└── cli
├── ArticleCommandViewController.ts
├── ArticlePrinter.ts
├── ArticleQueryViewController.ts
├── MenuPrinter.ts
└── state-modules
├── State.ts
├── View.ts
├── mobx
│ └── MobxRootState.ts
├── redux
│ ├── MyStore.ts
│ └── redux-module.ts
└── vanila
└── StateManager.ts
음… ArticleCommandViewController 코드부터 보여드리면서 말씀드리는게 가장 좋을 것 같습니다.
import { ArticleCreateUseCase } from "../../application/port/incoming/ArticleCreateUseCase";
import { CliInOut } from "../../../common/view/cli/CliInOut";
import { MenuPrinter } from "./MenuPrinter";
export class ArticleCommandViewController {
constructor(
private readonly cliInOut: CliInOut,
private readonly menuPrinter: MenuPrinter,
private readonly articleCreateUseCase: ArticleCreateUseCase
) {}
public rednerArticleForm = async (): Promise<void> => {
const title = await this.cliInOut.printAndGet("제목: ", false);
const content = await this.cliInOut.printAndGet("내용: ", false);
const { id } = this.articleCreateUseCase.create({
title,
content,
});
await this.cliInOut.printAndGet(this.menuPrinter.printArticleSaved(id));
};
}
ArticleCommandViewController는 CliInOut, MenuPrinter, ArticleCreateUseCase를 의존합니다. CliInOut은 Nodejs에서
기본으로 제공하는 readline 라이브러리를 한 번 감싼 클래스입니다. MenuPrinter는 명령줄에 출력할 텍스트를 제공하는… UI(User Interface)를
그리는 클래스라고 할 수 있습니다. 문자열을 리턴합니다. ArticleCreateUseCase는 이미 위에서 설명했듯이 인터페이스입니다.
Callback을 Promise로
import readline from "readline";
export class CliInOut {
constructor(private rl: readline.Interface) {
console.clear();
}
public printAndGet = (toPrint: string, clear = true): Promise<string> =>
new Promise<string>((resolve) => {
this.rl.question(toPrint, (answer) => {
if (clear) {
console.clear();
}
resolve(answer);
});
});
public print = (toPrint: string) => {
this.rl.write(toPrint);
};
}
readline.Interface의 question 함수는 첫 번째 매개변수로 명령줄에 출력할 문자열을 받고, 두 번째 매개변수로 사용자의 입력을 받은 뒤 실행하는
콜백 함수를 받습니다. 모든 콜백 함수는 프라미스로 변환할 수 있습니다. 왜냐하면 그것이 프라미스니까요…⭐
프라미스는 제어의 역전을 통해 콜백지옥을 해결하기 위해서 탄생했습니다. 콜백 함수 안에서 또 다른 콜백을 사용하고, 그 안에서 또 콜백을 사용하게 되면 인덴트가
한없이 늘어나는 지옥의 가독성을 체험할 수 있습니다. 프라미스를 사용하면 콜백 함수 안에서는 resolve() 혹은 reject()를 호출하는 일만 하면 됩니다.
콜백 함수 안에서 하던 일을 프라미스를 통해서 콜백 함수 밖으로 빼냅니다.
동기적으로 하던 일을 비동기적으로 처리하기 위해 콜백 함수를 만들었습니다. 이것이 첫 번째 제어의 역전입니다. 콜백 함수가 언제 불릴지는 우리가 결정할 수 없고 콜백 함수를 매개변수로 받는 함수에서 결정합니다. 우리는 프라미스를 사용해서 콜백 함수 내부에서 하던 일을 밖으로 빼냅니다. 이것이 두 번째 제어의 역전입니다. 콜백 함수는 결과를 전달하는 역할만 할 뿐, 그 이후의 과정은 콜백함수 바깥에서 진행합니다. 우리는 프라미스를 통해서 잃었던 제어권을 다시 찾아올 수 있습니다.
제어의 역전 관점에서 프라미스를 설명하는 더 자세한 글은 카일 심슨의 『You Don’t Know JS: this와 객체 프로토타입, 비동기와 성능』9 ‘3장 프라미스’를 참고하세요.
상태 관리
제가 작성한 애플리케이션은 두 군데에서 상태관리를 합니다. 첫 번째 상태 관리자는 ArtilceInMemoryRepository입니다. 이 클래스에서는 도메인 객체의
상태를 관리합니다. UI를 그리다 보면 현재 UI가 어떤 상태에 있는지 표현해야 할 필요가 생깁니다. 저는 View라는 값 타입과 State 인터페이스를 사용하는
StateManager 클래스를 만들었습니다.
export type View =
| "HOME"
| "ARTICLE_LIST"
| "ARTICLE_DETAIL"
| "ARTICLE_FORM"
| "EXIT";
export interface State {
view: View;
selectedArticleId: number;
}
type과 interface의 차이는 무엇일까요? 제가 생각하는 가장 큰 기능적인 차이는 type은 상속이 불가능하고 interface는 상속이 가능하다는
것입니다. 그리고 View처럼 값을 타입으로 사용하려면 interface는 불가능하고 type을 사용해야 합니다. 이 외의 차이들도 있습니다:
https://www.typescriptlang.org/docs/handbook/2/everyday-types.html#differences-between-type-aliases-and-interfaces
type과 interface모두 자바스크립트로 컴파일하면 사라지는 정보들입니다. 많은 경우에 type이 interface를 대체할 수 있고, 조금 더 엄격한
부분이 있기 때문에 interface를 사용하지 않고 type만 사용하도록 컨벤션을 정하는 경우도 있습니다. 저는 개인의 선호에 따라 혼용해서 사용해도 상관
없다는 입장입니다.
아래는 제가 직접 구현한 StateManager 입니다.
import { Constants } from "../../../../../Constants";
import { createInitialState, State } from "../State";
export class StateManager {
constructor(private state: State = createInitialState()) {}
public home = (answer: string) => {
switch (answer) {
case "1":
this.setState({ view: "ARTICLE_LIST" });
break;
case "2":
this.setState({ view: "ARTICLE_FORM" });
break;
case "x":
this.setState({ view: "EXIT" });
break;
}
};
public articleList = (answer: string) => {
switch (answer) {
case "":
break;
case Constants.GO_BACK_COMMAND:
this.setState({ view: "HOME" });
break;
default:
this.setState({
view: "ARTICLE_DETAIL",
selectedArticleId: parseInt(answer),
});
break;
}
};
public articleDetail = () => {
this.setState({ view: "ARTICLE_LIST", selectedArticleId: -1 });
};
public articleCreate = () => {
this.setState({ view: "HOME", selectedArticleId: -1 });
};
public getState = (): State => ({ ...this.state });
private setState = (newState: Partial<State>) => {
this.state = {
...this.state,
...newState,
};
};
}
주목해야 하는 부분은 getState와 setState입니다. state 객체를 외부효과에서 보호하기 위해 getState는 state를 복사해서 새로운 객체를
내보냅니다. setState는 새로운 상태를 매개변수에 받는데, 이 매개변수를 그대로 this.state에 대입하지 않고 새로운 객체를 만들어 this.state에
대입합니다. getState로 내보낸 객체의 상태가 변하더라도 this.state에는 영향이 없고, setState의 매개변수로 들어온 newState의 상태를
바깥에서 바꾸더라도 setState 함수가 실행된 이후라면 this.state에 영향이 없습니다. this.state를 외부효과에서 철저히 보호합니다.
ArticleCommandController는 StateManager를 의존하지 않습니다. 이 두 클래스는 article 디렉토리 바깥의
ApplicationByStateManager에서 사용합니다.
import { ArticleCommandViewController } from "./article/view/cli/ArticleCommandViewController";
import { ArticleQueryViewController } from "./article/view/cli/ArticleQueryViewController";
import { StateManager } from "./article/view/cli/state-modules/vanila/StateManager";
export class ApplicationByStateManager {
constructor(
private readonly stateManager: StateManager,
private readonly articleQueryViewController: ArticleQueryViewController,
private readonly articleCommandViewController: ArticleCommandViewController
) {}
public run = async () => {
for (;;) {
switch (this.stateManager.getState().view) {
case "HOME":
await this.articleQueryViewController
.renderHome()
.then((input) => this.stateManager.home(input));
break;
case "ARTICLE_LIST":
await this.articleQueryViewController
.renderArticleList()
.then((input) => this.stateManager.articleList(input));
break;
case "ARTICLE_DETAIL":
await this.articleQueryViewController
.renderArticleDetail(this.stateManager.getState().selectedArticleId)
.then(this.stateManager.articleDetail);
break;
case "ARTICLE_FORM":
await this.articleCommandViewController
.rednerArticleForm()
.then(this.stateManager.articleCreate);
break;
case "EXIT":
process.exit(0);
}
}
};
}
StateManager의 상태에 따라서 ArticleQueryController, ArticleCommandController를 호출합니다. 컨트롤러 클래스가 입출력 담당하고,
사용자의 입력은 다시 StateManager에 들어가서 다음 상태를 유발합니다. 원래 컴퓨터가 유한 상태 기계(Finite State Machine)10이지만, 특히 UI와
관련된 코드를 작성할 때 이 개념이 유용합니다.
StateManager를 직접 구현해서 애플리케이션을 만들기도 했지만, redux와 mobx를
사용해서 만들어보기도 했습니다(ApplicationByRedux, ApplicationByMobx 클래스). 이 두 라이브러리는 react에 의존하지 않기 때문에 독립적으로
사용할 수 있습니다. 대놓고 유한 상태 기계의 구현을 돕는 라이브러리인 xstate로도 애플리케이션을 작성해보는 것을 추천합니다.
처음부터 ViewController와 StateManager를 나누는 방식으로 작성하지는 못했습니다. 명령줄 입출력 관련 코드, UI 상태 코드, 유스케이스 호출 코드가
한데 버무려진 상태로 작동하는 애플리케이션을 작성하고, 이 애플리케이션을 복사해서 redux를 사용하는 애플리케이션을 만들었습니다. 만들어놓고 보니
두 애플리케이션 코드에 중복되는 부분이 보였고, 이 중복을 없애면서 ViewController와 StateManager가 탄생했습니다. ViewController를
UI 상태와 완전히 분리해서 여러 가지 상태 관리 모듈을 사용해서 UI를 구현할 수 있게 만들었습니다. 이후엔 테스트를 작성하기 쉬운 형태로 클래스를 정리했습니다.
저는 ‘동일한 기능을 하는 애플리케이션을 여러 가지 상태 관리 라이브러리를 사용해서 구현하고 싶다’라는 요구사항이 있었기 때문에 리팩토링을 진행했습니다. 만약 실제 비즈니스 상황이었고 한 가지의 상태 관리 라이브러리만 사용해도 충분했다면… 아마 저는 리팩토링을 하지 않았을 겁니다. 언젠가 비즈니스에 여유가 있을 때 자기만족을 위해서 해볼 수는 있을 것 같네요.
만약 UI를 작성하는데도 TDD 방법론을 따라 테스트를 먼저 작성했다면 어땠을까요? 기능을 구현하기 전에 테스트를 먼저 설계해야 했으므로 속도가 더딘 것처럼 느껴지고 머리가 아프겠지만… 아마 지금과 같은 구조를 훨씬 더 빨리 만들 수 있지 않았을까 생각합니다.
개발자가 속는 더 잘못된 거짓말은 “지저분한 코드를 작성하면 단기간에는 빠르게 갈 수 있고, 장기적으로 볼 때만 생산성이 낮아진다”는 견해다. 이 거짓말을 받아들인 개발자는 엉망인 코드를 만드는 태세에서, 나중에 기회가 되면 엉망이 된 코드를 정리하는 태세로 전환할 수 있다고 자신의 능력을 과신하게 된다. 하지만 이는 그저 진실을 오인한 것일 뿐이다. 진실은 다음과 같다. 엉망으로 만들면 깔끔하게 유지할 때보다 항상 더 느리다. 시간 척도를 어떻게 보든지 관계없이 말이다.
…
또한 TDD를 적용한 날이 적용하지 않은 날보다 대략 10% 빠르게 작업이 완성되었고, 심지어 TDD를 적용한 날 중 가장 느렸던 날이 TDD를 적용하지 않고 가장 빨리 작업한 날보다도 더 빨랐다.
- 로버트 C. 마틴, 송준의. 클린 아키텍처. 서울: 인사이트, 2019. p11
뭐야, 메인 함수가 없는데요?
View를 구현하기 전까지, 즉 domain, application, adapter 디렉토리를 구현할 때까지는 메인 함수를 작성하지 않고 TDD방식으로 애플리케이션을
작성했습니다. 파일 트리를 간결하게 보여드리기 위해 테스트 파일을 제외했지만, 테스트 파일까지 포함해서 파일 트리를 출력한다면 다음과 같습니다.
article
├── adapter
│ └── outgoing
│ └── persistence
│ ├── ArticleInMemoryRepository.ts
│ ├── ArticlePersistenceAdapter.ts
│ └── __test__
│ ├── ArticleInMemoryRepository.unit.test.ts
│ └── ArticlePersistenceAdapter.unit.test.ts
├── application
│ ├── ArticleCommandService.ts
│ ├── ArticleQueryService.ts
│ ├── __test__
│ │ ├── ArticleCommandService.unit.test.ts
│ │ └── ArticleQueryService.unit.test.ts
│ └── port
│ ├── incoming
│ │ ├── ArticleCreateUseCase.ts
│ │ ├── ArticleGetUseCase.ts
│ │ ├── ArticleListUseCase.ts
│ │ ├── ArticleRequest.ts
│ │ ├── ArticleResponse.ts
│ │ └── __test__
│ │ ├── ArticleRequest.unit.test.ts
│ │ ├── ArticleResponse.unit.test.ts
│ │ └── ArticleResponseFixture.ts
│ └── outgoing
│ ├── ArticleLoadPort.ts
│ └── ArticleSavePort.ts
├── domain
│ ├── Article.ts
│ ├── ArticleImpl.ts
│ └── __test__
│ ├── ArticleFixture.ts
│ └── ArticleImpl.unit.test.ts
└── view
└── cli
├── ArticleCommandViewController.ts
├── ArticlePrinter.ts
├── ArticleQueryViewController.ts
├── MenuPrinter.ts
├── __test__
│ ├── ArticlePrinter.unit.test.ts
│ ├── ArticleCommandViewController.unit.test.ts
│ └── MenuPrinter.unit.test.ts
└── state-modules
├── State.ts
├── View.ts
├── __test__
│ └── State.unit.test.ts
├── mobx
│ ├── MobxRootState.ts
│ └── __test__
│ ├── MobxLearningTest.unit.test.ts
│ └── MobxRootState.unit.test.ts
├── redux
│ ├── MyStore.ts
│ ├── __test__
│ │ └── redux-module.unit.test.ts
│ └── redux-module.ts
└── vanila
├── StateManager.ts
└── __test__
└── StateManager.unit.test.ts
여기서 테스트까지 얘기하진 않겠습니다, 테스트만으로도 책 한권은 거뜬하니까요. 켄트 벡의 『테스트 주도 개발』11과 블라디미르 코리코프의 『단위 테스트』12에 제가 테스트에 대해서 하고 싶은 이야기 모두가, 그리고 훨씬 깊은 이야기가 있습니다. 이규원님의 현실 세상의 TDD 는 TDD에 대한 의심과 불신을 씻어내주는 글입니다. 향로님의 jest.mock 보다 ts-mockito 사용하기 (feat. Node.js)도 꼭 읽어보세요.
지금까지는 계속 클래스만 만들었습니다. 클래스들은 다른 클래스나 인터페이스를 의존합니다. 결국 어딘가에서 이 클래스과 인터페이스들의 관계를 엮어서 동작하게
해야 합니다. 여기서 ApplicationContext가 등장합니다.
-
로버트 마틴의 책 클린 아키텍처 에는 다음과 같은 챕터가 있다: ‘30장 데이터베이스는 세부사항이다’, ‘31장 웹은 세부사항이다’, ‘32장 프레임워크는 세부사항이다’ ↩ ↩2
-
Konuklar, Tugce. “Hexagonal (Ports & Adapters) Architecture”. Idealo Tech Blog (blog), 2021년 4월 20일. ↩
-
ACID(원자성Atomicity, 일관성Consistency, 고립성Isolation, 지속성Durability). 트랜잭션의 정상 작동을 보장하기 위해 지켜야 하는 4가지 성질. ↩
-
Cahill, Michael J., Uwe Röhm and Alan D. Fekete. “Serializable isolation for snapshot databases”. ACM Transactions on Database Systems 34, 호 4 (2009년 12월 14일): 20:1-20:42. https://doi.org/10.1145/1620585.1620587. ↩
-
“Serializable Transactions | CockroachDB Docs”. 2022년 3월 18일에 접근함. https://www.cockroachlabs.com/docs/stable/demo-serializable.html. ↩
-
카일 심슨, 이일웅. You Don’t Know JS: this와 객체 프로토타입, 비동기와 성능. 서울: 한빛미디어, 2017. ↩
-
“유한 상태 기계”. 위키백과, 우리 모두의 백과사전, 2022년 3월 7일. https://ko.wikipedia.org/wiki/유한_상태_기계 ↩
results matching ""
No results matching ""
